
개인적인 논문해석을 포함하고 있으며, 의역 및 오역이 남발할 수 있습니다. 올바르지 못한 내용에 대한 피드백을 환영합니다 :)
1. Introduction
- Visual Document Understanding (VDU)
- PDF 형태 혹은 이미지 형태인 디지털 문서에 대한 이해
- entity grouping, sequence labeling, document classification
- 문서에서 OCR(Optical Character Recognition)을 수행하는 연구는 많지만 VDU를 위해선 구조와 레이아웃을 모두 반영해야 함
- 최근 Transformer 구조를 통해 text, spatial, image를 모두 반영하여 이를 해결하려는 연구가 다수 진행
- 각 연구마다 text, spatial, image의 세 가지 modality를 결합하는 방식이 각자 다름
- NLP(Natural Language Processing)에서 그랫듯이 unsupervised 방식으로 사전 학습(pre-training)하고 downstream task에 맞게 미세 조정(fine-tuning)하는 것이 일반적
- PDF 형태 혹은 이미지 형태인 디지털 문서에 대한 이해
- Cross-modality feature correlation
- multi-modal 학습은 텍스트를 임의의 범위의 시각적 영역에 매핑하는 과정
- “사람”이라는 단어를 설명하는 텍스트 modality와 달리, 이에 해당하는 visual modality는 단순 픽셀 집합에 불과함
- 때문에 modality간의 feature 상관관계를 모델링하는 것이 어려움
- multi-modal 학습은 텍스트를 임의의 범위의 시각적 영역에 매핑하는 과정
- DocFormer
- Architecture 특징
- multi-modal self-attention
- shared spatial embeddings
- pre-training with 3 unsupervised multi-modal tasks
- multi-modal masked language modeling task (MM-MLM)
- learn-to-reconstruct (LTR)
- text describes image (TDI)
- Architecture 특징
[@ Contributions]
- 문서 이미지에서 text, visual, spatial features를 결합할 수 있는 새로운 형태의 multi-modal attention layer 제안
- Multi-modal feature collaboration을 위한 세 가지 unsupervised pre-training task 제안, 이 중 두 가지는 해당 분야에 새로운 방법: MM-MLM, LTR
- end-to-end로 학습 가능하고 사전 학습된 object detection 모델을 사용하지 않음
- VDU의 4가지 downstream task에 대해 DocFormer는 state-of-the-art 성능을 달성
- 문서 이미지에서 텍스트를 추출하기 위한 Custom OCR 모델을 사용하지 않음
2. Background
[@ Grid based methods using CNN]
- 구조적인 형태가 많은 문서(예: forms, tables, receipts, invoices)
- invoice(송장) 문서에서 표의 형태를 통해 유형 분류 수행
- 송장번호, 날짜, 공급업체 이름, 주소, …
[@ BERT transformer-encoder based methods]
- LayoutLM
- BERT 아키텍처를 문서 이미지에 맞게 수정하여 document understanding 수행
- 2D spatial coordinate embeddings
- 1D position
- text token embeddings
- visual features and its bounding box coordinates for each word token, obtained using a Faster-RCNN
- 11M 개의 unlabeled page를 통해 사전학습
- BERT 아키텍처를 문서 이미지에 맞게 수정하여 document understanding 수행
- LayoutLMv2
- LayoutLM을 향상
- 모델에 visual feature가 입력되는 방식을 개선
- text token에 더해주는 대신 개별적이고 독립적인 token으로 처리
- pre-training task를 추가
- LayoutLM을 향상
- BROS
- 2D spatial embeddings
- graph-based classifier
- text token 사이의 엔티티 상관관계 예측에 사용
[@ Multi-modal transformer encoder-decoder based methods]
- Layout-T5
- a question answering task on a database of web article document images
- TILT
- convolutional features + T5 architecture
3. Approach
[@ Conceptual Overview]
- Joint Multi-Modal
- vision feature와 text feature가 하나의 긴 시퀀스로 결합
- cross-modality feature correlation의 측면에서 self-attention의 학습이 어려울 것임
- Two-Stream Multi-Modal
- 각 modality를 담당하는 별도의 branch를 사용
- 이미지와 텍스트의 결합이 끝에 이르러서야 발생하기 때문에 이상적인 방법이 아님
- Single-Stream Multi-Modal
- visual feature도 text token과 동일한 형태로 만들어 서로 더해줌
- vision과 language feature는 서로 다른 유형의 데이터, 단순하게 더하는 것은 부자연스러운 방법
- Discrete Multi-Modal (paper’s)
- visual, spatial feature를 text feature에서 분리하여 반복되는 각각의 transformer layer마다 residual하게 입력
- text feature에 대한 visual, spatial feature의 영향이 각 transformer layer마다 달라질 것을 기대하였음

3.1. Model Architecture
[@ features extract & processing]
- Visual features
- 입력 이미지 $v\in \mathbb R^{3\times h\times w}$를 ResNet50 CNN으로 feature 추출: $f_{cnn}(\theta, v)$
- ResNet50의 4번째 블록 feature 사용 $v_{l_4} \in \mathbb R^{c\times h_l \times w_l}$
- $v_{l_4} = f_{cnn}(\theta, v)$
- $c=2048, h_l = {h\over 32}, w_l = {w\over 32}$
- $1\times 1$ convolution을 통해 채널 $c$ 축소
- transformer encoder의 입력 token의 수인 $d$로 축소
- $(c, h_l, w_l) \to (d, h_l, w_l)$
- flatten & linear transformation
- $(d, h_l, w_l) \to (d, h_l \times w_l) \to (d, N)$
- $d=768, N=512$
- 입력 이미지 $v\in \mathbb R^{3\times h\times w}$를 ResNet50 CNN으로 feature 추출: $f_{cnn}(\theta, v)$
- Language features
- OCR로 추출한 텍스트 $t$를 tokenizing
- word-piece tokenizer 사용
- $t_{tok} = {[CLS], t_{tok_1}, t_{tok_2}, …, t_{tok_n}}, (n=511)$
- 한 문서에서 나타나는 토큰 수가
- 511보다 큰 경우 나머지는 무시
- 511보다 작은 경우 나머지 공간은 $[PAD]$ 토큰으로 채움, $[PAD]$ 토큰은 self-attention 계산 과정에서 무시
- trainable embedding layer $W_t$로 사영
- 해당 레이어의 가중치는 LayoutLMv1의 사전학습 가중치를 사용
- OCR로 추출한 텍스트 $t$를 tokenizing
- Spatial features
- 각 단어 $k$개 대하여 bounding box 좌표값 $b_k=(x_1, y_1, x_2, y_2, x_3, y_3, x_4, y_4)$
- 위 $b_k$만 사용하는 것에 그치지 않고 추가적인 정보를 더 인코딩
- bounding box의 높이 $h$, 너비 $w$
- 네 모서리와 중점에 대해 word box간의 상대적 거리
- \[A_{rel}=\left\{A^{k+1}_{num}-A^k_{num}\right\}\]
- $A\in (x, y); num\in(1, 2, 3, 4, c)$
- $c$는 중점
- $k$ index는 top-left $\to$ bottom-right 방향으로 증가
- 즉, $k+1$번째 word box는 $k$번째 word box의 우하향 방향에 위치
- $P^{abs}$: 1D positional encoding
- $x$와 $y$, visual feature $\bar V$와 language feature $\bar T$에 대해 각각 따로 임베딩 행렬을 두고 따로 학습하여 계산
- spatial 영향은 modality 별로 각각 발생할 것이라고 생각
[@ Multi-Modal Self-Attention Layer]
- a transformer encoder $f_{enc}$ outputs a multi-modal feature representations $\bar M$ of the same shape as each of the input features ($d=768, N=512$)
- $\eta$는 transformer의 파라미터
- $i$번째 입력 토큰에 대한 $l$번째 transformer layer의 multi-modal feature
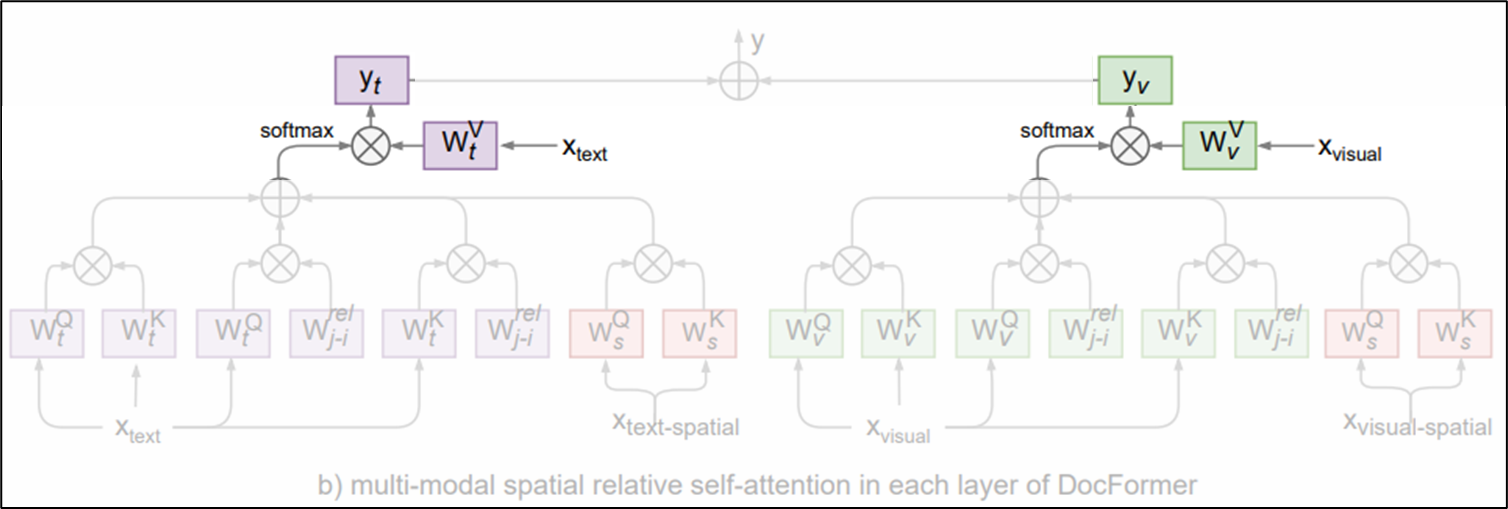
generalization을 위한 $\sqrt d$와 $l$번째 레이어의 것이라는 표기를 제거하여 간단하게 나타내면,
\[\alpha_{ij} = (x_i W^{Q})(x_j W^{K})^T\]여기서 visual feature와 text feature에 대해 각각 다른 연산 흐름을 갖는다.
- attention distribution for visual feature
- $x^v$는 각 토큰의 visual feature
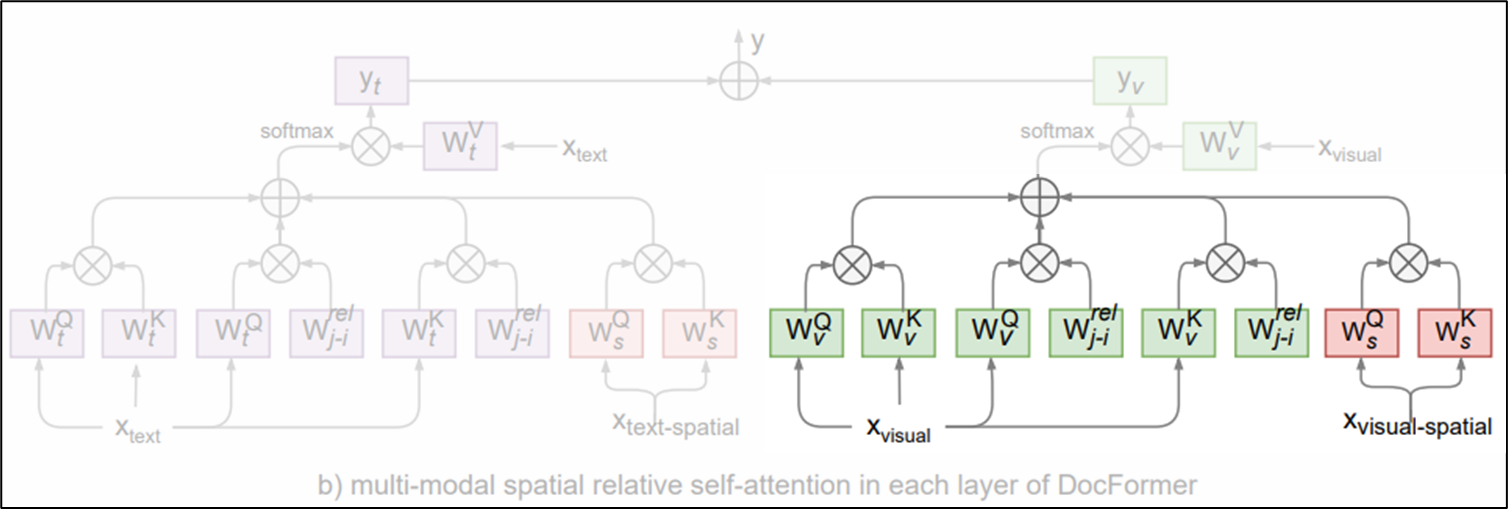
query 1D relative attn.,key 1D relative attn.,visual spatial attn.을 모두 더해주어 local feature를 포착하는데 힘을 쏟음
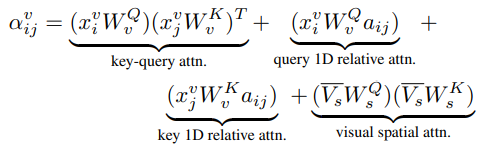
- attention distribution for text feature
- 위 visual feature에서의 연산과 거의 비슷함
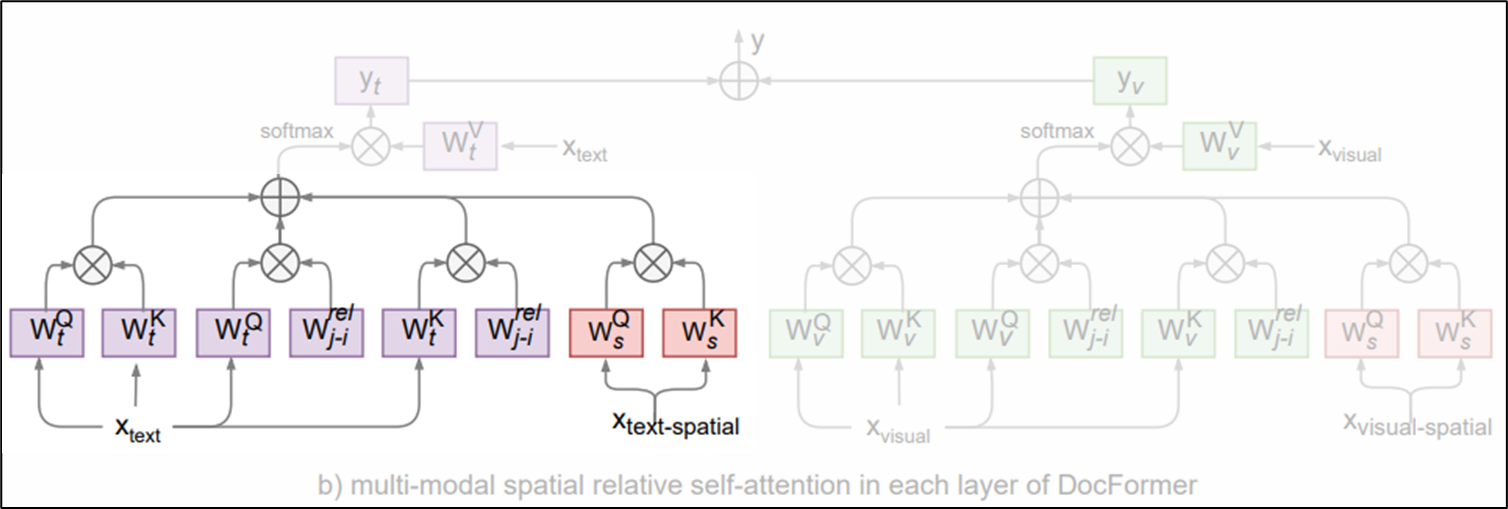
- 단, 입력 토큰 $x_i$는 이전 transformer layer의 output인 multi-modal feautre (만약 첫 번째 레이어라면 word embedding일 것)
- 모든 transformer layer에 visual feature는 모두 동일하게 입력이 주어지지만, text feature는 transformer layers stack을 따라 흐르기 때문이다. (아래 그림 참조)
 visual feature는 각 transformer layer에 따로따로 투입, text feature(word embedding)은 transformer layers stack을 타고 흐름
visual feature는 각 transformer layer에 따로따로 투입, text feature(word embedding)은 transformer layers stack을 타고 흐름
- multi-modal feature output
- $l$번째 transformer layer의 output은 $\bar M_l = \hat V_l + \hat T_l$
본 논문에서 강조하는 점 중 하나는 Spatial embeddings를 위한 attention 가중치를 공유하고 있다는 것인데, 이는 위 attention 연산 흐름을 나타내는 그림에 spatial Query, Key matrix가 visual과 text 모두 분홍색으로 같은 색으로 칠하는 것으로 강조하고 있고, 아래 실험(4. Experiments)을 통해 이에 대한 효과를 입증하고 있다.
3.2. Pre-training
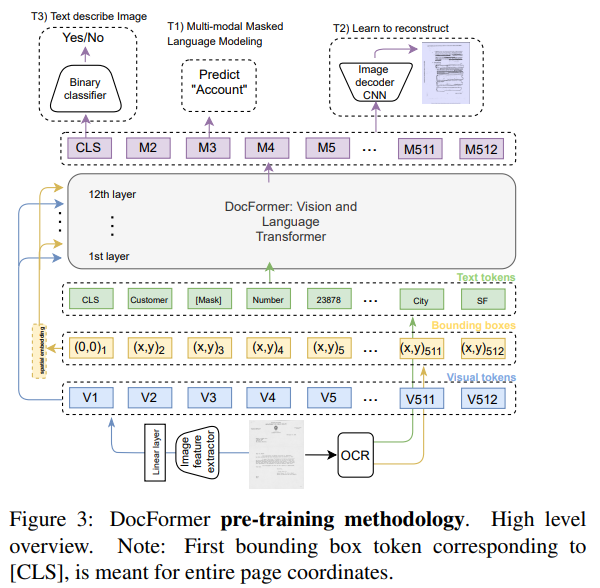
Multi-Modal Masked Language Modeling (MM-MLM)
- 기존 BERT에서 소개되었던 기존 Masked Language Modeling (MLM) task를 개선
- 텍스트 시퀀스 $t$에서 일부를 마스킹한 corrupted 시퀀스 $\tilde t$
- multi-modal feature embedding인 $\bar M$을 바탕으로 원래 시퀀스 $t$로 복구하는 task
- LayoutLMv2와 같은 연구에서는 마스킹한 텍스트에 해당하는 이미지 영역도 같이 마스킹하였으나, 본 연구에서는 이미지 영역에 대한 마스킹을 하지 않음
- 마스킹 비율은 BERT의 것과 동일
- Cross-entropy loss로 학습
Learn To Reconstruct (LTR)
- MM-MLM task의 이미지 버전 (image reconstruction)
- multi-modal feature embedding $\bar M$을 shallow decoder로 투입, 원래 입력 이미지로 복구
- auto-encoder를 통한 image reconstruction과 비슷함
- smooth-L1 loss로 학습
Text Describes Image (TDI)
- 위 두 사전학습 task(MM-MLM, LTR)가 local features에 집중하였던 것과 다르게 global features에 집중한 task
- multi-modal feature embedding $\bar M$을 입력으로 단일 linear layer를 통과해 binary classification 수행
- 한 배치 내에서 80%는 올바른 text-image pair, 20%는 잘못된 text-image pair를 구성하도록 하였음
- 단, 잘못된 text-image pair가 구성될 경우 LTR task의 loss는 무시
- binary cross-entropy로 학습
final pre-training loss
\[L_pt = \lambda L_{MM-MLM} + \beta L_{LTR} + \gamma L_{TDI}\] \[\lambda=5, \beta=1, \gamma=5\]4. Experiments
- 개요
- 모든 실험에 걸쳐 training set을 통해 fine-tuning
- test나 validation set에 대한 결과
- 데이터셋 별로 별도의 특화된 hyper-parameter tuning은 진행하지 않았음
- Models
- 기존 transformer encoder model에 대한 terminology를 따름
- 12개의 transformer layer가 있는 경우 -base 모델 (768 hidden state and 12 attention heads)
- 24개의 transformer layer가 있는 경우 -large 모델 (1024 hidden state and 16 attention heads)
- text and spatial features만 사용하는 모델에 대해서도 실험
- DocFormer의 유연성 강조
- visual features가 포함됨으로써 더 나아지는 모습 강조
- 기존 transformer encoder model에 대한 terminology를 따름
4.1. Sequence Labeling task
- FUNSD dataset
- form understanding을 위한 데이터셋
- 문서 내 각 요소들의 entity 유형 및 클래스가 레이블링 되어 있음 (아래 그림 참조)
- 149 train / 50 test pages
- form understanding을 위한 데이터셋
- Sequence labeling task
- 각 구성 요소의 클래스를 예측하는 task
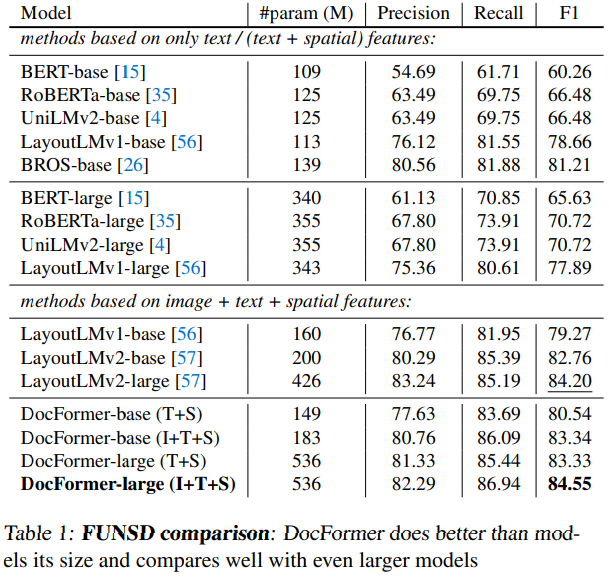 LayoutLMv2가 11M의 데이터로 사전학습한 것에 반해 DocFormer는 5M의 데이터로 학습한 결과임을 강조하고 있음
LayoutLMv2가 11M의 데이터로 사전학습한 것에 반해 DocFormer는 5M의 데이터로 학습한 결과임을 강조하고 있음
 Qualitative result
Qualitative result
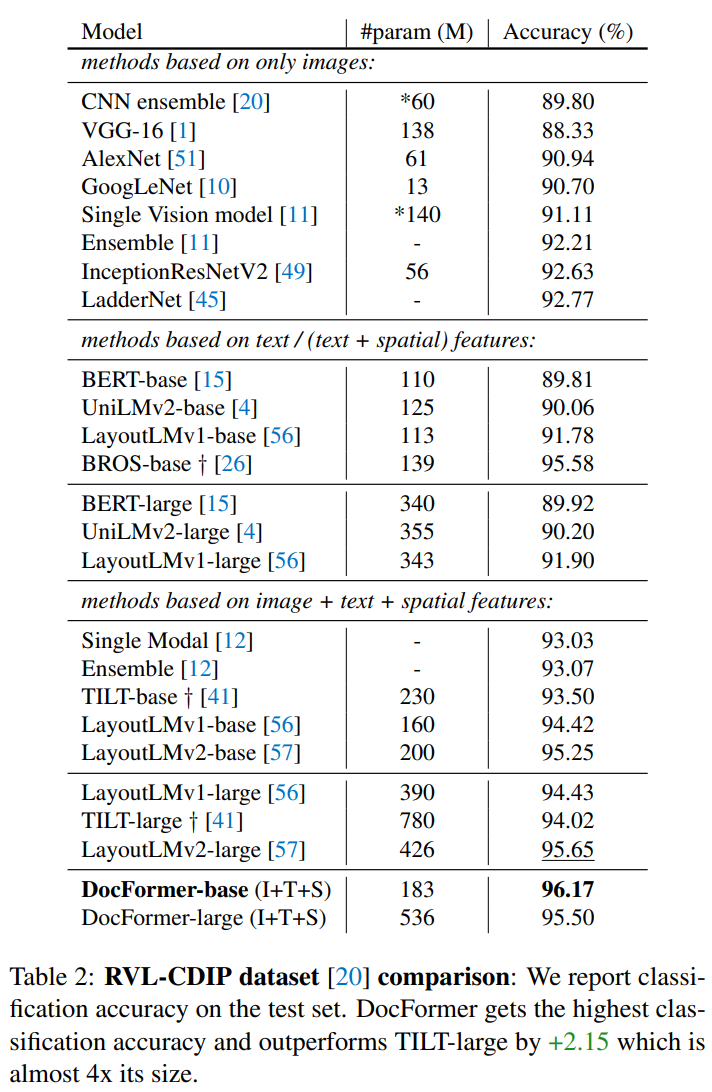
4.2. Document Classification task
- RVL-CDIP dataset
- 320,000 train / 40,000 validation / 40,000 test
- grayscale images
- 16 classes
- text 및 layout 정보는 Tesseract OCR로 도출
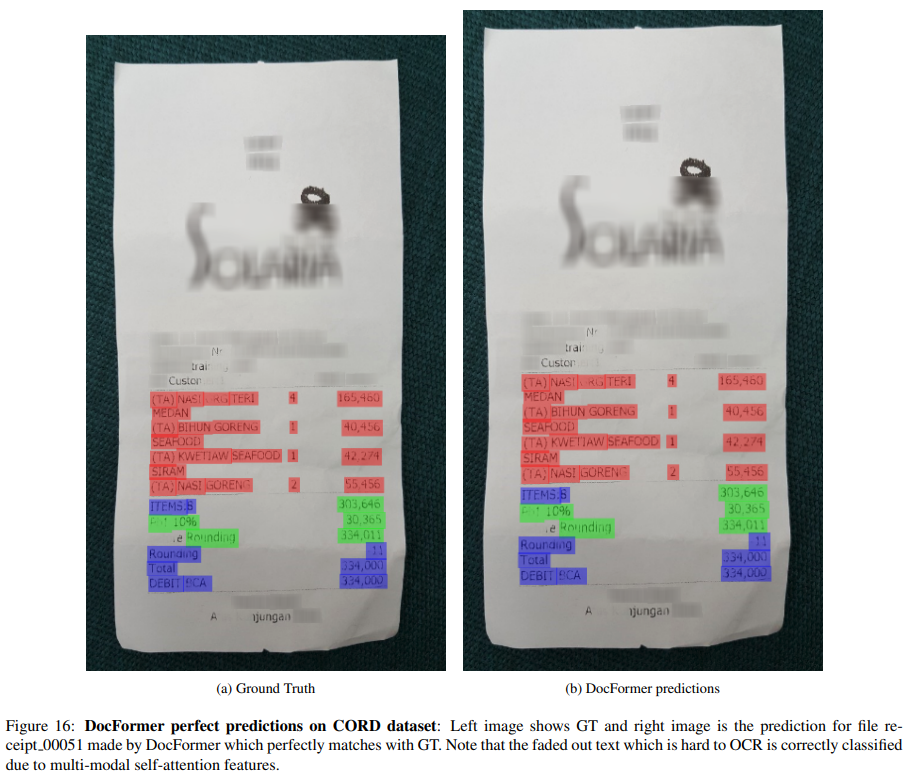
4.3. Entity Extraction Task
- OCR로 추출한 정보들(text, spatial)과 문서 이미지(image)를 조합
- 각 entity의 정보를 예측하는 task
- CORD dataset
- 영수증 이미지 데이터셋
- 30 fields under 4 categories
- Kleister-NDA dataset
- legal NDA documents
- 4개의 fixed labels를 추출하는 데이터셋

4.4. More Experiments
Shared or Independent Spatial embeddings?
- vision and language modalities 간의 sharing spatial embedding의 효과
- sharing spatial embedding을 통해 feature correlation을 학습할 수 있다고 주장

Do our pre-training tasks help?
- 비교적 학습 데이터 수가 적은 데이터셋에서는 사전 학습이 필요한 것으로 보임

Does a deeper projection head help?
- 위 실험 결과들은 모두 downstream task에 단일 linear layer만으로 예측한 결과임
- ($fc\to ReLU \to LayerNorm \to fc$) 형태의 더 깊은 projection head를 사용하는 것의 효과에 대한 실험
- 학습 데이터가 비교적 많은 데이터셋에 대해 효과를 보였음

4.5. Ablation Study
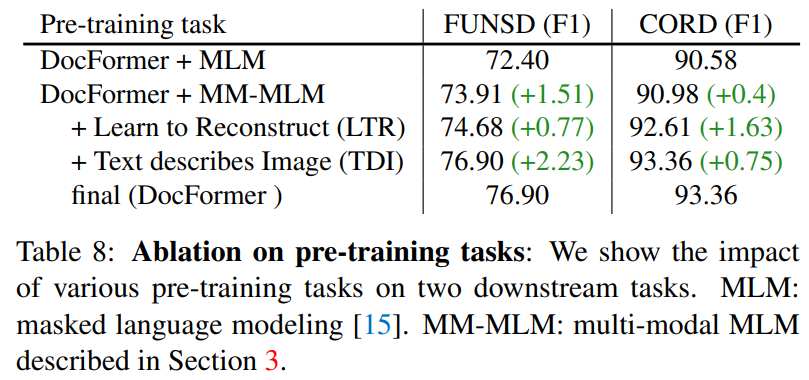 pre-training task의 유무에 따른 결과 비교
pre-training task의 유무에 따른 결과 비교
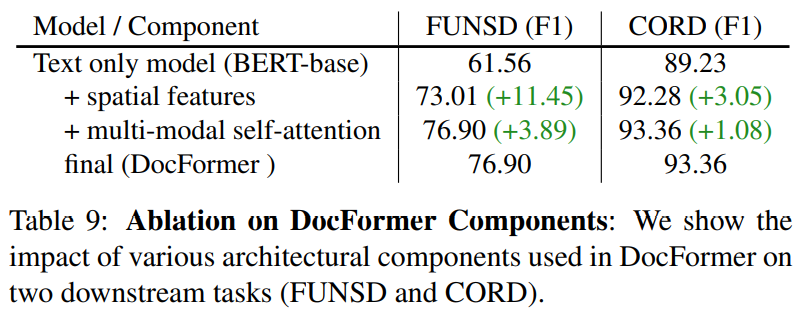 DocFormer의 구성요소 유무에 따른 결과 비교
DocFormer의 구성요소 유무에 따른 결과 비교
5. Conclusion
- DocFormer 제안, 다양한 Visual Document Understanding tasks에 대한 end-to-end trainable transformer based model
- multi-modal attention 방법론 제안
- 두 가지 새로운 vision-plus-language 사전학습 task 제안
- 실험을 통해 DocFormer가 비교적 규모가 작은 모델임에도 4가지 데이터셋에 대해 SOTA 성능을 달성
- Future works
- multi-lingual 환경에 대한 DocFormer 연구
- info-graphics, maps, web-pages와 같은 다양한 형태의 문서에 대한 연구
Microsoft의 LayoutLM를 잇는 Amazon의 document를 위한 transformer 모델이다. LayoutLM과 비교했을 때 사용하는 문서의 요소들이나 방법들이 크게 다르지는 않는 것 같다. 다만 그 형태를 조금씩 바꾸었음에도 11M $\to$ 5M으로 사전학습에 사용한 데이터셋 수를 크게 줄인 것은 흥미로운 부분이다.
Comments powered by Disqus.