
개인적인 논문해석을 포함하고 있으며, 의역 및 오역이 남발할 수 있습니다. 올바르지 못한 내용에 대한 피드백을 환영합니다 :)
1. Introduction
- Visual Document Understanding (VDU)
- 스캔된 형태 혹은 사진으로 촬영한 형태의 전자 파일 형태의 문서에 대한 이해
- 문서 처리 자동화를 위해 필요한 중요한 단계임
- document classification, parsing, visual question answering 등등
- Optical Character Recognition (OCR) 시스템
- 딥러닝을 활용한 OCR 시스템이 발전함에 따라 Document understanding을 위한 기존 연구들은 독립적인 OCR 모듈을 사용해 텍스트를 추출
- 해당 연구들의 문제점
- OCR은 유지비용이 많이 든다: 최근의 OCR 모델들은 GPU를 사용하기도 하며 큰 규모의 학습 데이터셋이 필요함
- OCR이 발생시키는 error는 후속 프로세스에 부정적인 영향을 미친다: 한국어나 일본어와 같이 비교적 OCR이 어려운 언어에 대해 빈번하게 발생함
- Donut: Document understanding transformer
- raw 입력 이미지만으로 원하는 형태의 출력으로 매핑할 수 있도록 모델링
- end-to-end로 학습하며, 다른 모듈(OCR은 물론)에 의존적이지 않음
- SynthDoG: Synthetic Document Generator
- 합성 문서 이미지 생성기
- 모델 사전학습에 꼭 필요한 대규모 문서 이미지를 생성할 수 있음
- 대규모 실제 문서 이미지에 대한 의존성을 완화
[@ Contributions]
- Visual Document Understanding을 위한 새로운 방법론 제시
- 최초로 OCR-free한 transformer 아키텍처에 기초한 방법을 제안
- end-to-end로 학습 가능
- SynthDoG제안 & 모델의 사전학습을 위한 간단한 사전학습 task 제시
- 광범위한 실험 설계
- 공공 벤치마크 뿐만 아니라 저자들의 산업 서비스에서 수집한 데이터셋에 대해서도 분석
- 논문에서 제시하는 방법론이 뛰어남을 보임
2. Method
2.1. Preliminary: background
- 기존 VDU는 BERT의 출현과 함께 Computer Vision(CV)과 Natural Language Processing(NLP)를 결합한 transformer 형태의 방법들이 제안되어 왔음
- 일부 문제점
- 대규모의 실제 문서 이미지 데이터셋을 사용해야함
- 독립적인 OCR 엔진에 의존하여 텍스트를 추출해야함 (VDU 모델의 전체 성능을 유지하려면 OCR 엔진을 유지보수 해야하는 추가적인 노력이 필요함)
2.2. Document Understanding Transformer
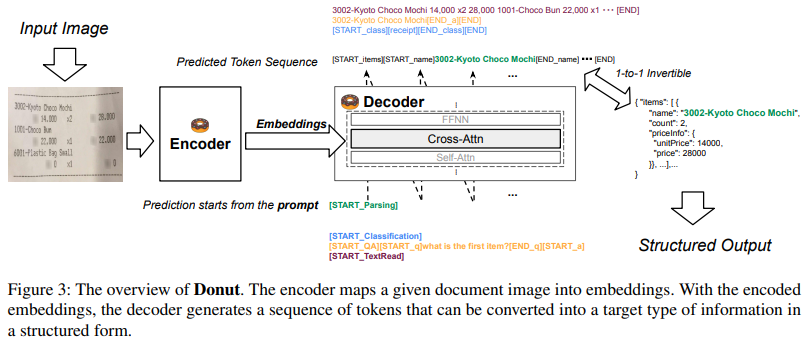
- Encoder
- visual encoder: $\mathbf x \in \mathbb R^{H\times W\times C} \to \left( \mathbf z_i \mid \mathbf z_i \in \mathbb R^d, 1\le i \le n \right)$
- $n$은 feature map size 혹은 이미지 패치 수
- $d$는 transformer의 입력 벡터 차원 수
- 본 연구에서는 Swin Transformer를 사용
- visual encoder: $\mathbf x \in \mathbb R^{H\times W\times C} \to \left( \mathbf z_i \mid \mathbf z_i \in \mathbb R^d, 1\le i \le n \right)$
- Decoder
- textual decoder: ${\mathbf z} \to (\mathbf y_i)^m_1$
- $\mathbf y_i \in \mathbb R^v$: one-hot vector for the token $i$
- $v$: the size of token vocabulary
- $m$: a hyperparameter
- multilingual BART의 첫 4개의 레이어 사용
- textual decoder: ${\mathbf z} \to (\mathbf y_i)^m_1$
- Model Input
- Training phase
- teacher-forcing 방식으로 학습 진행
- Test phase
- GPT-3와 같이 토큰 시퀀스 생성
- 각각의 downstream task에 맞게 약간의 special token으로 prompt를 제공하여 출력할 수 있도록 함
- prompt?: GPT-3는 약간의 예시를 제공받고 이에 파생되는 결과물을 예측하는데, 이 때 GPT-3가 제공받는 제한된 소스 및 샘플 혹은 예시를 prompt라고 함
- Training phase
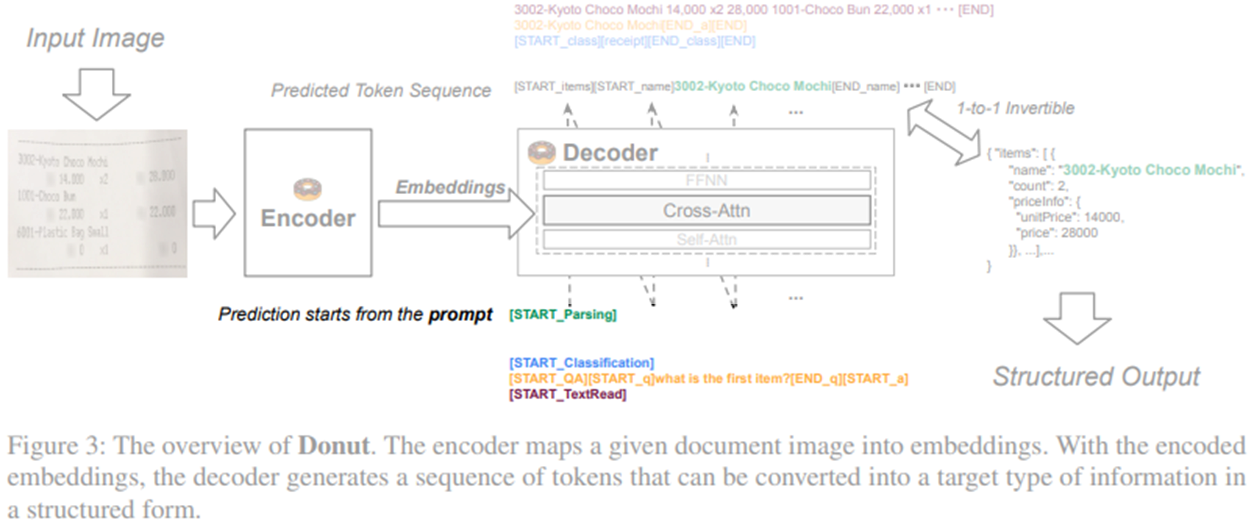 input prompt의 예시
input prompt의 예시
- Output Conversion
- downstream task의 종류와 관계없이 최종 결과물로 JSON 파일 형태로 변환하였음
[START_*],[END_*]토큰을 활용해 파싱- ex.)
[START_class],[receipt],[END_class]$\to${"class": "receipt"}
- ex.)
[START_name]토큰만 출현하고,[END_name]토큰은 출현하지 않았을 경우 $\to$"name"필드 요소는 출현하지 않은 것으로 처리하였음
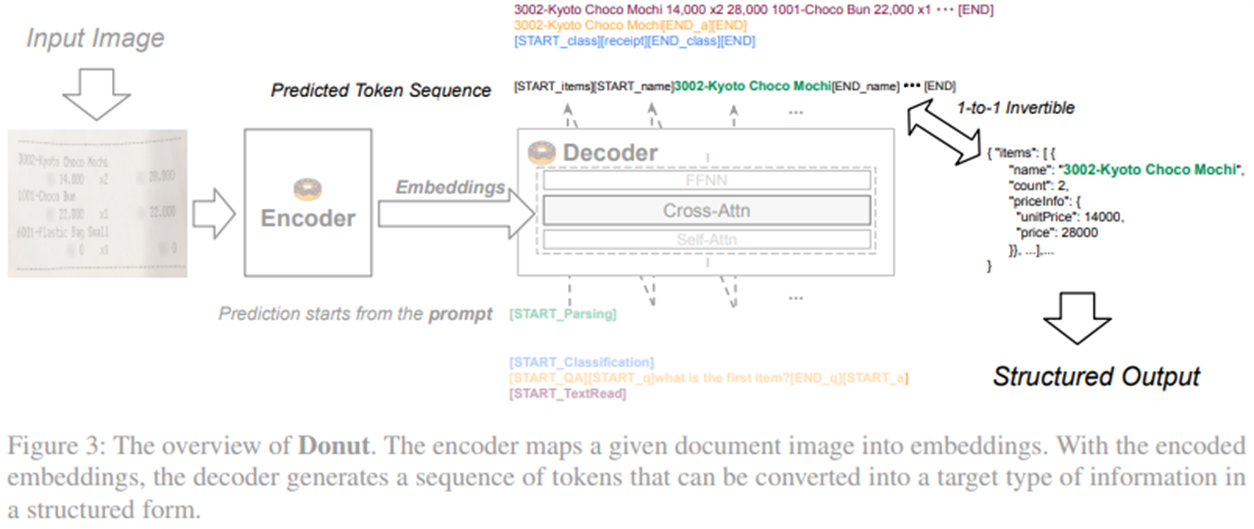 모델이 예측한 token sequence에서 JSON 파일로 변환하는 예시
모델이 예측한 token sequence에서 JSON 파일로 변환하는 예시
2.3. Pre-training
- Synthetic Document Generator (SynthDoG)
- 이미지 렌더링 파이프라인은 SynthTIGER (Synthetic Text Image GEneratoR)의 것을 따름
- Background
- ImageNet의 이미지를 샘플링하여 배경으로 사용
- texture of Document
- 문서의 종이 질감은 수집된 사진에서 샘플링함
- Text
- 단어나 문장들은 Wikipedia에서 수집
- Layout
- rule based 랜덤 패턴으로 실제 문서의 레이아웃을 따라하고자 했음
- Task
- SynthDoG가 렌더링한 1.2M개의 합성 문서 이미지로 학습
- 영어, 일본어, 한국어가 이미지 생성에 사용되었으며 각 언어당 400K개의 이미지를 생성
- 사전학습 task로는 단순히 이미지 내의 문자를 top-left $\to$ bottom-right 방향으로 텍스트를 잘 읽어내는 task를 수행
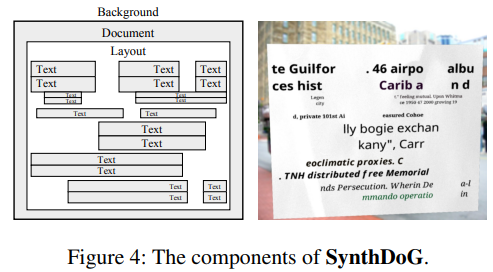 SynthDoG로 렌더링한 이미지 예시
SynthDoG로 렌더링한 이미지 예시
2.4. Applications
- 사전학습 단계에서 how to read를 학습했다면 미세 조정 단계에서는 how to understand를 학습
- 섹션 2.2. Output Conversion의 형태, JSON 파일 형태를 생성할 수 있도록 미세 조정
3. Experiments and Analysis
3.1. Downstream tasks and Datasets
예측 단계에서도 모든 downstream task에 대해 JSON 파일에 나타난 정보를 읽어들이는 형식으로 진행한다.

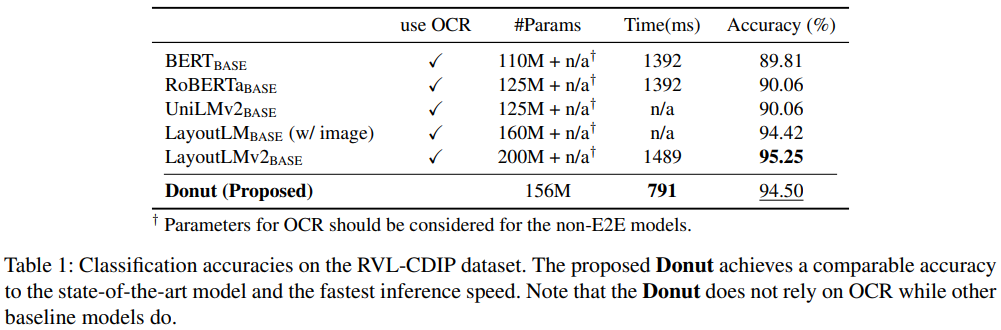
3.1.1. Document Classification
- RVL-CDIP dataset
- 320,000 train / 40,000 validation / 40,000 test
- grayscale images
- 16 classes
- classification
- 타 연구에서는 token 임베딩에 softmax를 씌워 class label을 예측
- 본 연구에서는 JSON 파일에서 class label 정보를 읽어들이는 방식으로 예측
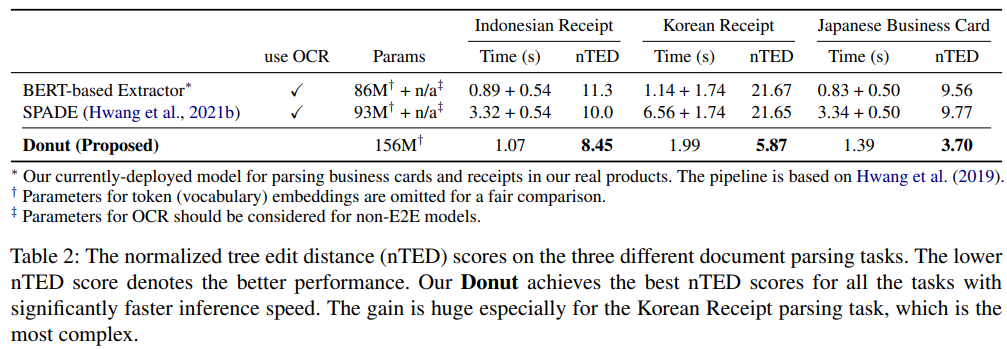
3.1.2. Document Parsing
- 문서 내 layouts, formats, contents를 예측하는 task
- Indonesian Receipts dataset
- 1K Indonesian receipt images
- OCR annotations 포함
- 1K Indonesian receipt images
- Japanese Business Cards dataset (In-Service Data)
- 20K 일본 명함 이미지
- JSON 형태로 구조 정보 포함
- Korean Receipts dataset (In-Service Data)
- 55K 한국 영수증 이미지
- JSON 형태로 구조 정보 포함
- 타 데이터셋보다 복잡한 형태를 갖춤
3.1.3. Document VQA
- 문서 이미지와 주어진 질문을 입력 받아 올바른 답변을 출력해야하는 task
- DocVQA dataset
- 12K document images 내 50K questions 포함
- training: validation: test = 39,463: 5,349: 5,188 images
- test set에 대한 ANLS (Average Normalized Levenshtein Similarity) 수치 제시
3.2. Common Settings
- pre-train on the 1.2M synthetic document images for an epoch
- mini-batch size: 8
- Adam optimizer
- initial learning rate is selected from $2e-5$ to $8e-5$
- learning rate is scheduled
- 스케줄링 방법은 제시하지 않았음
- OCR 의존적인 타 모델에 대한 OCR 세팅
- OCR 레이블이 지정되어 있는 데이터셋의 경우 특별한 언급이 없을 때 정답 레이블을 이용
- 몇몇 task에 대해서는 Microsoft OCR API 사용
- document parsing task에서는 CLOVA OCR 중 영수증 및 명함 이미지에 적합한 모델을 적용
3.3. Results
3.3.1. Document Classification
3.3.2. Document Parsing
3.3.3. Document VQA
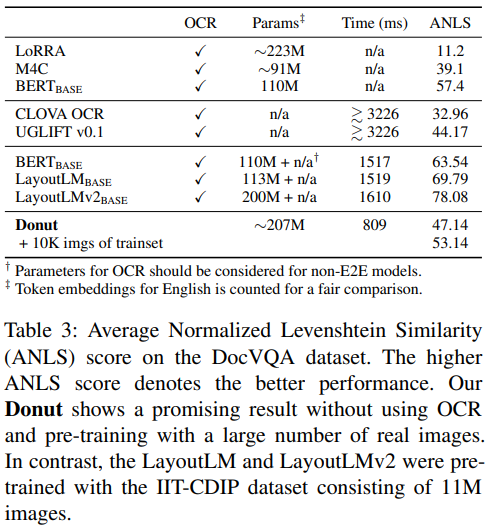
- 그룹 구분
- 첫 번째 그룹: 데이터셋에서 제공하는 OCR 레이블 사용
- 두 번째 그룹: CLOVA OCR 사용
- 세 번째 그룹: Microsoft OCR API 사용
- 성능
- 성능이 만족스럽지 못하지만 추론 시간 면에서 앞섬
- 실제 문서 이미지를 사용한 사전학습
- 마지막으로 10K개의 실제 문서 이미지로 Donut 모델을 사전학습하였을 때, 성능 향상 폭이 매우 컷음
- 실제 문서 이미지로 학습하는 것이 중요함
5. Concluding Remarks
- Donut
- 새로운 형태의 visual document understanding에 대한 end-to-end 방법론
- 입력 이미지를 곧바로 구조화된 JSON 파일로 매핑
- 다른 OCR 엔진이나 큰 규모의 실제 문서 이미지에 의존적이지 않음
- SynthDoG
- 사전학습 데이터를 만들 수 있는 합성 문서 생성기 제안
- 실험 결과
- 논문에서 제안하는 방법이 cost effective함을 보임
- future work
- document understanding과 관련한 다른 도메인이나 task로 확장
Naver CLOVA AI 팀의 문서 이미지를 다루는 태도를 알 수 있었다.
pre-training task가 단순 텍스트 리딩에 그친 것을 마주하고 다소 실망한 감이 있었지만, 확실히 OCR의 도움을 벗어내려는 접근과 output의 형태를 JSON으로 통일하려는 접근 자체는 매우 재미있었다.
pre-training task가 단순한 이유 때문인지 Document VQA에 대한 성능은 많이 떨어지는 듯 (애초에 네이버에서 서비스하고 있는 국내 영수증이나 일본 명함에 specific하게 접근한 것으로 보인다). 사실 타 연구들은 텍스트 정보까지 활용하는 multi-modal 모델인 만큼 이에 파생되는 많은 pre-training task를 적용할 수 있겠지만, 이미지만 사용하는 Donut의 경우에는 그 종류가 제한적이라는 면에서 이해는 된다.
빨리 github에서 공개된 코드를 마주할 날이 오길 바란다.
4. Related Work
4.1. Optical Character Recognition
- 초기 text detection method
- CNN으로 local segments를 잡고, 휴리스틱한 방식으로 segment들을 결합하여 최종 detection line으로 만드는 형태를 취함
- 이후에 object detection을 적극적으로 사용
- region proposal, bounding box regression 개념 적용, 텍스트 탐지
- 최근
- 텍스트 고유의 동질성, 지역성에 집중
- 텍스트 내부의 구성요소, 즉 sub-text(혹은 알파벳)를 탐지하고 하나의 텍스트 인스턴스로 결합하는 형태
- curved, long, oriented 텍스트에 대응할 수 있었음
- Text recognition
- 위에서 탐지한 영역을 잘라내 CNN으로 인코딩-디코딩하여 문자를 해석
4.2. Visual Document Understanding
- Classification
- 초기에는 일반적인 이미지처럼 문서 이미지도 처리 (CNN의 활용)
- BERT의 출현 이후 CV and NLP 조합이 트렌드로 자리잡음
- 여기에는 OCR 엔진을 통한 텍스트 추출이 필수적
- OCR로 추출한 텍스트를 token sequence의 형태로 하여 BERT의 입력으로 제공 (가능하다면 visual feature도 사용)
- 아이디어는 간단하지만 훌륭한 성능을 보였음
- Document parsing
- 초기
- 구조화된 형식의 문서에 대한 알맞은 database scheme에 따라 사람이 parsing하는 형태
- 최근
- OCR을 통한 parsing이 활용되고 있음
- 초기
- Visual Question Answering
- 대부분의 SOTA 방법론은 BERT류의 transformer 구조를 띄고 있음
- 주어진 이미지에 질문에 대한 답이 나타나지 않을 경우가 있음
- 위 우려점에 대응하기 위한 생성 기반의 방법도 제안한 연구가 있음
- 대부분의 SOTA 방법론은 BERT류의 transformer 구조를 띄고 있음
Comments powered by Disqus.