
개인적인 논문해석을 포함하고 있으며, 의역 및 오역이 남발할 수 있습니다. :)
1. Introduction
Deep learning 방식의 NER은 많은 데이터를 필요로 합니다. NER task에 대한 레이블링 작업은 token-level의 레이블링이 필요하기 때문에 시간적, 금전적 비용이 많이 들고, 작업자의 실수가 발생할 수도 있습니다. 이러한 요소들이 의료 도메인과 같은 전분 분야 특정 도메인에 대한 NER을 어렵게 만드는 요인입니다. 때문에 선행 연구에서는 labeled data가 한정적인 경우를 대응하기 위한 연구들을 진행했습니다.
- continually pre-train
- 큰 규모의 unlabeled data를 사용하는 방법
- 거대한 unlabeled open-domain data에 대해 사전학습을 진행한 BERT가 대표적 예시
- 이러한 open-domain pre-trained model은 특정 도메인 고유의 정보의 모델링 능력이 떨어짐
- continually pre-train: Lee et al. (2020); Gururangan et al. (2020)
- 이미 학습된 open-domain pre-trained model을 이어서 사전 학습하는 방법을 제안
- open-domain pre-trained model이 특정 도메인의 지식을 갖도록 하기 위함
- 큰 규모의 unlabeled data를 사용하는 방법
- weak supervision
- 도메인 지식 베이스에서 자동적으로 label을 생성하는 방법
- Shang et al. (2018)
- “Biomedical dictionary”를 통해 unlabeled Biomedical documents에 레이블을 자동 생성
사람이 직접 생성하는 strongly labeled data는 위에서 언급한 것처럼 비용이 많이 소요되기 때문에 적은 양일 경우가 많습니다. 반면에 엄청난 양의 large scale unlabeled data와 전문 분야 domain knowledge를 이용해 자동적으로 생성하는 weakly labeled data는 그 양을 많이 확보할 수 있죠.
논문에서 저자들은 Weak labels가 아래 세 가지 특징을 가진다고 말합니다.
- incompleteness: 세상에 존재하는 모든 entity를 지식 베이스가 모두 커버할 수 없음
- labeling bias: 자동적으로 생성되는 weak label은 entity가 아닌 것을 entity라고 할당하는 등의 노이즈가 발생
- ultra-large scale: 자동으로 생성될 수 있기 때문에 strong label에 비해 그 수가 많음
위 특징을 가진 Weakly labeled data를 잘 활용할 수 있는 방법은 무엇일까요? 논문에서는 ultra-large scale의 특성으로 인해 유용한 도메인 지식은 확보할 수 있으나, 동시에 많은 양의 데이터가 incompleteness, labeling bias의 특성을 가지고 있기 때문에 이에 따른 노이즈의 영향도 많아질 수 밖에 없다고 말합니다. 때문에 NER 모델의 학습에 (Strongly + Weakly)의 단순히 조합하는 방식이나 label에 따른 가중치를 매겨 조합하는 방식 모두 incompleteness, labeling bias 특성이 야기하는 노이즈에 영향을 받을 수 있다고 말합니다.
이를 해결하고자 논문에서는 프레임워크 NEEDLE을 제안합니다.
- NEEDLE; Noise-aware wEakly supErviseD continuaL prE-training
- Stage 1
- open-domain pre-trained model을 target domain에 대해 사전학습
- 특정 도메인(target domain)의 큰 규모의 unlabeled data를 이용
- Stage 2
- target domain의 지식 베이스를 통해 unlabeled data에 weak label을 자동 생성
- (Strongly labeled data + Weakly labeled data)를 이용 NER 학습
- Stage 3
- Strongly labeled data만으로 다시 한번 NER 학습
- Stage 1
Contributions
- (Strong labels + Weak labels)의 단순한 조합, 가중치를 부여한 조합을 사용해 학습하는 경우 모델 성능이 떨어질 수 있음을 보임
- 압도적인 양(ultra-large scale)을 가진 weak label의 노이즈 영향 때문
- 세 단계의 프레임워크 NEEDLE을 제안, 압도적인 양의 weak label의 영향을 줄임
- 다양한 실험 환경
- E-commerce query (온라인 쇼핑몰 검색어) NER task
- Biomedical NER task
- multi-lingual 환경
- 다양한 실험 환경
2. Preliminaries
2.1. Named Entity Recognition
NER(Named Entity Recognition)은?
- $N$개의 tokens로 이루어진 한 문장 $\mathbf X = [x_1, …, x_N]$에 대해서 한 토큰 범위 (a span of tokens) $s = [x_i, …, x_j] (0 \le i \le j \le N)$를 하나의 엔티티(an entity)로 가집니다.
- $\mathbf X$에 대한 레이블 시퀀스(a sequence of labels) $\mathbf Y = [y_1, …, y_N]$는
BIOtag를 가지는 토큰 시퀀스입니다.BIOXentity type의 $s$의 첫 토큰은B-X- 이후 $s$의 다른 토큰들은
I-X - entity가 아닌 토큰들은
O
BIO로 구성된 a sequence of token labels $\mathbf Y$를 예측하는 것이 NER(Named Entity Recognition) task라고 할 수 있습니다.- Supervised NER
- $M$개의 주어진 문장과 이미 label이 할당된 집합 $\set{(\mathbf X_m, \mathbf Y_m)}^M_{m=1}$, NER 모델 $f(\mathbf X; \theta)$에 대해 아래의 목적함수 최적화하며 학습하는 전형적인 딥러닝의 학습 기반 방법입니다.
- \[\hat\theta = \arg\min_{\theta} {1 \over M} \sum^M_{m=1} l(\mathbf Y_m, f(\mathbf X_m; \theta))\]
- $l(\cdot, \cdot)$: cross-entropy loss
- Weakly Supervised NER
- 반면에 $\set{\mathbf Y_m}^M_{m=1}$을 자동으로 생성한 weakly labeled data로 교체하여 위와 동일한 목적함수를 통해 학습하는 방법을 말합니다.
3. Method
3.1. Stage 1: Domain Continual Pre-training over Unlabeled Data
선행 연구를 따라 the large in-domain unlabeled data \(\set{\tilde{\mathbf X}_m}^{\tilde M}_{m=1}\)을 사용해 사전 학습된 언어 모델 \(f_{LM}(\cdot; \theta_{enc}, \theta_{LM})\)을 추가 학습하는 과정입니다. 논문에서는 Masked Language Model 사전 학습 task를 이용해 학습한다고 언급했습니다. 이를 통해 Introduction에서 언급했던 특정 분야 도메인에 모델을 적응할 수 있게 할 수 있습니다.
- masked language model: 언어 모델의 사전 학습에 가장 많이 사용되는 학습 방법 (Devlin et al. (2019) 참조)
- $\theta_{enc}$: 언어 모델 encoder의 parameter, 예) BERT의 parameter
- $\theta_{LM}$: token classification head의 parameter, 예) fully-connected layer의 parameter
3.2. Stage 2: Noise-Aware Continual Pre-training over both Strongly and Weakly labeled Data
본격적으로 NER을 학습하기 이전에 대규모의 weakly labeled data를 만들어내야 합니다. 논문에서는 전문 용어 사전(dictionary)을 구축하고 이 용어 사전 내 단어와 정확한 string matching이 발생하는 구간을 태깅하는 방식을 사용합니다. 이에 대한 자세한 설명은 논문의 Appendix E를 참고하면 되겠습니다.
자동 생성된 weakly labeled data: \(\set{(\tilde{\mathbf X}_m, \tilde{\mathbf Y}_m^w)}^{\tilde M}_{m=1}\) 를 사용해 BERT-CRF구조의 모델로 본격적인 NER 학습이 진행됩니다. 이 때 모델의 가중치는 Stage 1의 BERT parameter(\(\theta_{enc}\)) + 랜덤하게 초기화된 CRF layer의 parameter(\(\theta_{CRF}\)) 조합으로 구성됩니다.
이 모델에 약간의 Strongly labeled data를 통한 NER 학습을 진행시킨 뒤(Initial model) 논문의 주요 기여점이라 할 수 있는 Weak Label Completion과 Noise-Aware Loss Function의 테크닉을 적용해 Strongly + Weakly labeled data 모두 사용해 본격적인 학습이 시작됩니다.
- Weak Label Completion
- 해당 테크닉은 Initial model의 예측 값으로 weak label을 대체하는 과정이라고 요약할 수 있는데, 간단하게 입력값(inputs)과 출력값(output)을 수식으로 표현할 수 있습니다.
- inputs
- a sentence $\tilde{\mathbf{X}} = [x_1, …, x_N]$
- the original weak labels $\tilde{\mathbf{Y}^w} = [y_1^w, …, y_M^w]$
- the predictions from the initial model $\tilde{\mathbf Y}^p = \arg\min_{\mathbf Y} l(\mathbf Y, f(\tilde{\mathbf X}; \theta_{enc}, \theta_{CRF})) = [y_1^p, …, y_N^p]$
- output
- $\tilde{\mathbf Y}^c = [y_1^c, …, y_N^c]$
- \[y_i^c = \begin{cases} y_i^p && \text{if } y_i^w = \bigcirc \\ y_i^w && \text{otherwise}\end{cases}\]
- weak label이
O; non entity로 태깅되었다면, 모델의 예측 값을 사용 - weak label이
B-X혹은I-X와 같이 entity로 태깅되었다면 weak label을 그대로 사용
- 누락된 entity를 Strong label에 학습한 모델의 힘을 빌려 weakly label의 불완전성을 보완하는 효과를 얻을 수 있을 것 같습니다.
- Noise-Aware Loss Function
- 저자들은 Introduction에서도 언급했듯이 weak labels은 ultra-large scale의 특성을 가지므로 불완전한 weakly labeled data 분포에 모델이 지나치게 적합되는 것을 완화하고자 했습니다. 따라서, Weak Label Completion 테크닉으로 수정된 corrected weak labels $\tilde{\mathbf Y^c}$의 신뢰도를 기반으로 한 손실함수를 제안합니다.
confidence: $\hat P(\tilde{\mathbf Y}^c = \tilde{\mathbf Y} \mid \tilde{\mathbf X})$: $\tilde{\mathbf Y}^c$가 실제 label이 될 것으로 추정되는 확률confidence가 높은 경우 log-likelihoodconfidence가 낮은 경우 log-unlikelihood
- 저자들은 Introduction에서도 언급했듯이 weak labels은 ultra-large scale의 특성을 가지므로 불완전한 weakly labeled data 분포에 모델이 지나치게 적합되는 것을 완화하고자 했습니다. 따라서, Weak Label Completion 테크닉으로 수정된 corrected weak labels $\tilde{\mathbf Y^c}$의 신뢰도를 기반으로 한 손실함수를 제안합니다.
confidence추정 (Appendix A)- corrected weak label의
confidence, $\hat P(\tilde{\mathbf Y}^c = \tilde{\mathbf Y} \mid \tilde{\mathbf X})$를 추정하는 과정은 Appendix A에서 다루고 있습니다. 최종적으로는 original weak label과 model prediction의 신뢰도의 선형 결합으로 추정하게 됩니다.- original weak label이 model prediction과 일치하는 경우 weak label의 신뢰도 가중
- original weak label이 model prediction과 일치하지 않는 경우 model prediction의 신뢰도를 가중
- 이 때 model prediction의 신뢰도; $\hat P(\tilde{\mathbf Y}^p = \tilde{\mathbf Y} \mid \tilde{\mathbf X})$의 추정은 CRF score의 분포에 histogram binning을 적용하고 각 bin에 대해 validation set에 대한 결과를 바탕으로
confidence를 추정합니다. 추정 방법에 대해서는 정확히 이해하지 못하였습니다…ㅜ confidence가 너무 높은 경우에는 이를 완화하는 후처리 작업도 진행했습니다.- $P(\tilde{\mathbf Y}^c = \tilde{\mathbf Y} \mid \tilde{\mathbf X}) = \min(0.95, P(\tilde{\mathbf Y}^c = \tilde{\mathbf Y} \mid \tilde{\mathbf X}))$
- corrected weak label의
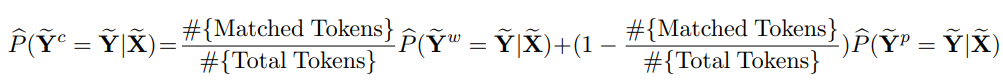 corrected weak label의 신뢰도는 weak label & model prediction의 신뢰도 선형 결합으로 정의된다.
corrected weak label의 신뢰도는 weak label & model prediction의 신뢰도 선형 결합으로 정의된다.
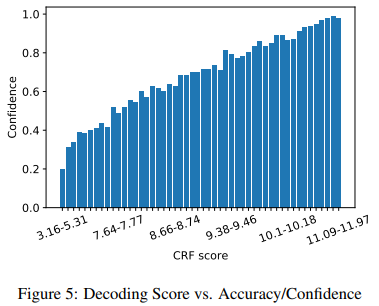 논문에서 제시한 예시, CRF score histogram bin과
논문에서 제시한 예시, CRF score histogram bin과 confidence의 상관관계를 확인할 수 있다.
- Noise-Aware Loss Function의 해석
- 이렇게 정의된 Noise-aware loss를 자세히 살펴보면 log-unlikelihood loss는 regularization term으로 보이고,
confidence는 loss term (여기서는 log-likelihood)과 regularization term (여기서는 log-unlikelihood) 사이의 가중을 결정하는 adaptive weight로 보이기도 합니다.
- 이렇게 정의된 Noise-aware loss를 자세히 살펴보면 log-unlikelihood loss는 regularization term으로 보이고,
- 최종 손실함수
- 최종적으로 Stage 2의 Initial model 학습에 strongly labeled data에 대해서는 일반적인 negative log-likelihood를, weakly labeled data에 대해서는 Noise-Aware Loss Function를 사용하게 됩니다.
3.3 Stage 3: Final Fine-tuning
Stage 2에서 Initial model을 만들었던 방법대로 Strongly labeled data에 다시 한 번 최종적으로 미세 조정하게 됩니다. Experiment 파트에서 이 효과를 설명하고 있습니다.
4. Experiments
- baseline models
- transformer-based open-domain pretrained models + CRF
- e.g.,
BERT,mBERT,RoBERTa-Large+ CRF
BIOtagging scheme으로 entity taggingAdamoptimizer
4.1. Datasets
- E-commerce query domain
- English NER
- 10 different entity types
- multilingual NER
- 12 different entity types
- unlabeled in-domain data & weak annotation
- 쇼핑 웹사이트(Amazon)의 사용자 행동 데이터를 수집
- English NER
- Biomedical domain
- unlabeled data
PubMed 2019 baseline수집
- weak annotation
- 수집한
dictionary에서 exact string matching을 통해 할당 dictionary수집 방법에 대해선 언급하지 않았음
- 수집한
- unlabeled data
- Weak labels performance
Table 1의 weak label이 strong(golden; 데이터셋이 제공하는 원래 label) label과 비교- E-commerce query domain에서 golden label에 비해
Recall값이 많이 떨어짐 - entity가 아닌 것을 entity로 태깅하는 경우가 많은 것으로 보임
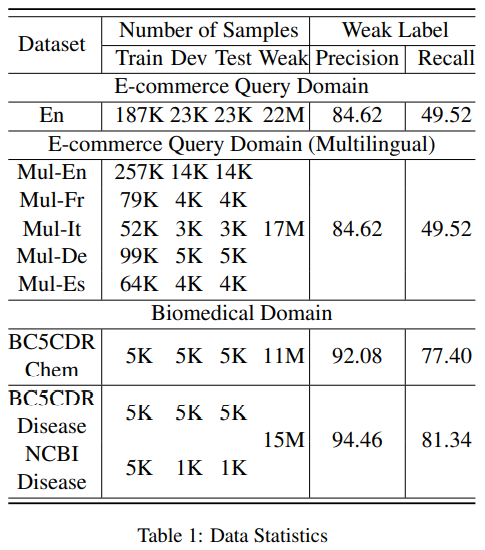 Table 1. E-commerce query domain의 Weak label의 퀄리티가 다소 떨어지는 것이 보인다.
Table 1. E-commerce query domain의 Weak label의 퀄리티가 다소 떨어지는 것이 보인다.
4.2. Baselines
- 모든 baseline 모델들은 in-domain unlabeled data에 continually pre-training을 진행하였습니다 (Stage 1). baseline 모델들에 대한 설명은 생략…
4.3. E-commerce NER
4.3.1. Main Results
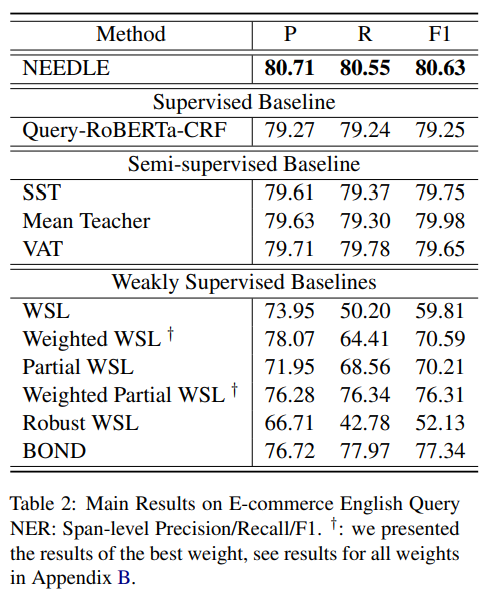
- weakly supervised baselines
- WSL(weakly supervised learning) 방식이 가장 성능이 떨어집니다. 이를 통해 weakly labeled data가 모델의 성능을 떨어뜨릴 수 있음을 알 수 있습니다.
- semi-supervised baselines
- 재미있게도, semi-supervised 방식이 오히려 supervised 방식의 성능을 능가하는데, 모델이 만들어낸 pseudo label이 weak label보다 좋을 수 있다고 추정할 수 있습니다. 최종적으로 NEEDLE은 semi-supervised 방식보다 성능이 좋았으며 pseudo label만을 사용하는 것보다 적절한 weak label을 함께 활용하는 것이 좋을 수 있다고 저자는 말합니다.
4.3.2. Ablation
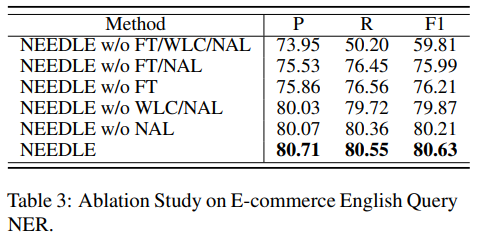 WLC - Weak label completion; NAL - Noise-aware loss function; FT - Final fine-tuning
WLC - Weak label completion; NAL - Noise-aware loss function; FT - Final fine-tuning
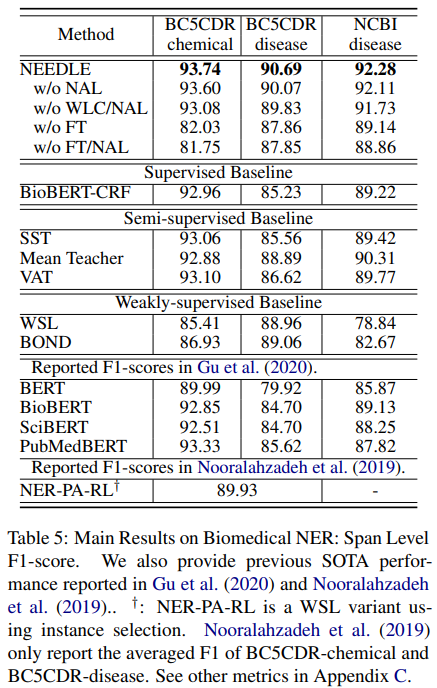
4.4. Biomedical NER
4.5. Analysis
- Size of Weakly Labeled Data
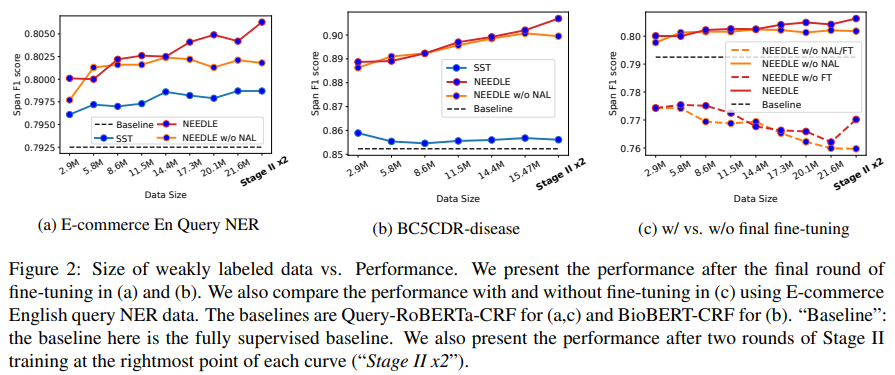
Figure 2(a)&Figure 2(b)- weakly labeled data의 양을 변경하며 실험했을 때, SST 방식은 성능 변화 폭이 미미했습니다. 반면 NEEDLE의 경우 weakly labeled data가 늘어날수록 성능 역시 향상되는 것을 볼 수 있고 NEEDLE이 weakly labeled data를 비교적 잘 활용하고 있다고 볼 수 있습니다.
Figure 2(c)- weakly labeled data의 수가 늘어날수록 fine-tuning 수행 유무에 따라 성능 차이가 벌어지는 것을 볼 수 있는데, final fine-tuning을 통해 학습할 유용한 정보가 있을 수 있음을 나타내고 있습니다.
- Two Rounds of Stage 2 Training
- Stage 3의 효과를 관찰한 저자들은 “Final fine-tuning” 대신 Stage 2의 학습을 한 번 더 수행하면 어떨지 실험을 진행했습니다. Stage 3 이후에,
- 새로운 모델로 weak label을 수정
- strongly + weakly labeled data로 noise-aware training을 지속
- strongly labeled data로 final fine-tuning
- 전체적인 학습 과정을 한 바퀴 더 돌렸을 때, 약간의 성능 향상이 있었습니다. 반면에 SST 방식, NEEDLE w/o NAL의 경우엔 변화가 없었음을 볼 수 있습니다. Noise-aware loss가 없는 경우 Noise-aware loss가 주요 요소인 Stage 2를 한 바퀴 더 굴린다는 개념이 의미없는 행위라고 생각이 드네요.
- Stage 3의 효과를 관찰한 저자들은 “Final fine-tuning” 대신 Stage 2의 학습을 한 번 더 수행하면 어떨지 실험을 진행했습니다. Stage 3 이후에,
- Size of Strongly Labeled Data
- 이번에는 Stronly labeld data의 수를 조절하며 실험하는데, 30% ~ 50%의 strongly labeled data가 있으면 fully supervised 방식의 성능에 도달함을 확인했습니다. 또한 20%의 데이터만으로 다른 60% 데이터를 사용한 baseline의 성능과 동등함을 근거로 들며 3배 정도 strongly labeled data에 대해 효율적이라고 주장하고 있네요.
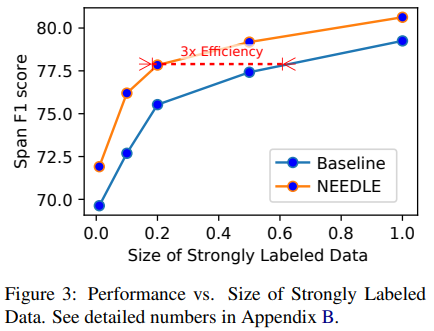 Strongly labeled data의 1% 만으로도 70% 초반의 성능을 보인다.
Strongly labeled data의 1% 만으로도 70% 초반의 성능을 보인다.
4.6. Weakly Label Errors in E-commerce NER
여기에서는 weak label이 유발하는 error에 대해서 이해하고, 이를 바로 잡을 수 있는 방법들에 대해 이야기합니다.
- Label Distribution Mismatch
- 먼저 저자들은 weak label의 분포가 strong label의 분포와의 차이가 심하다고 말합니다.
Figure 4에서도 볼 수 있듯이 분포가 많이 다릅니다. 반면 SST 방식의 모델이 만들어낸 pseudo label의 분포는 strong label의 분포와 거의 비슷한데, 이를 두고 SST 방식이 직접적으로 학습했을 때 성능이 좋은 이유라고 말합니다.
- 먼저 저자들은 weak label의 분포가 strong label의 분포와의 차이가 심하다고 말합니다.
- Systematical Error
- 저자들은 weakly labeled data의 시스템 내부적 error는 Stage 3; Final fine-tuning으로 쉽게 바로잡을 수 있다고 주장합니다. 여기서 예시로 들고 있는 “amiibo”는 “nintendo”사의
Product Line중 하나입니다. 따라서 “amiibo” 앞에 나타나는 “zelda”나 “wario”와 같은 entity는Misc타입으로 태깅되는 것이 옳습니다. 하지만 weak label에는 이를Color타입이라고 잘못 태깅되어 있어 corrected weak label에도Color타입이라고 잘못 태깅되어 있죠. - Stage 2에서는 이러한 샘플들을
Color + ProductLine조합으로 잘못 학습하지만 Stage 3에 가서Misc + ProductLine의 조합이라고 쉽게 수정될 수 있습니다. - 이와 같이 끝에 수정되는 방향이, 애초에 적은 양의
Misc + ProductLine의 옳게된 조합으로 학습되는 것보다 모델이 학습하기에 쉬운 방향이라고 주장하고 있습니다.
- 저자들은 weakly labeled data의 시스템 내부적 error는 Stage 3; Final fine-tuning으로 쉽게 바로잡을 수 있다고 주장합니다. 여기서 예시로 들고 있는 “amiibo”는 “nintendo”사의

- Entity
BIOSequence Mismatch in Weak Label Completion- Stage 2에서 Weak Label Completion 과정을 수행하는 과정에서
BIO태깅 시퀀스가 깨져버리는 경우가 발생할 수 있습니다. 예를 들어B-ProductType>O>O로 태깅되어 있던 시퀀스에서 첫 번째O태그가 Weak Label Completion 과정에 의해 수정되면서B-ProductType>I-Color>O로 깨져버리는 경우죠. - 저자들은 이러한 경우가 E-commerce English query 데이터의 1.39% 있었다고 말하고, 이 경우를 학습에서 제외하는 실험도 진행했습니다. 그 결과 F1 score 기준, Stage 2에서는 +1.07의 향상이 있었지만 마지막 Stage 3에서 -0.18의 성능 저하가 있었다고 밝힙니다.
- 이 결과 굳이 해당 샘플들을 제거하는 과정은 필요없다고 결론짓고 있습니다.
- Stage 2에서 Weak Label Completion 과정을 수행하는 과정에서
- Quantify the Impace of Weak Labels
- 여기에서는 구체적인 비교를 통해 weak label을 대하는 NEEDLE 프레임워크의 효용성을 밝힙니다.
- Stage 2의 Initial model은 2384개의 예측 오류를 가지는데, NEEDLE 프레임워크 종료 시점에는 이 중 454개의 오류가 해결되고 새로운 오류가 311개 추가됩니다. 여기에는 weak label만의 영향만 있는게 아니기 때문에 weak label에 대해서만으로 추리면 각각 171개, 93개로 관찰됩니다.
- 이 비율이 즉, “weak label을 바로 잡는 비율” = “NEEDLE이 바로 잡은 샘플 수” : “NEEDLE이 추가로 범한 예측 오류” = 171 : 93으로 그 비율이 $171/93 = 1.84 > 1$로 영향이 적지 않고 NEEDLE이 weak label에 효용성이 있다고 말하고 있습니다.
5. Discussion and Conclusion
본 연구는 fully weakly supervised 방식, semi-supervised 방식과 모두 연관성이 있습니다. 각각 weakly labeled data를 사용한다는 점, 전체 데이터셋 중 일부만 레이블이 할당되어 있다는 점에서 말이죠.
Fully weakly supervised NER 방식이 fully supervised 방식에 비해 성능이 떨어짐을 꼬집고 fully weakly supervised 방식은 실제 애플리케이션에는 적합하지 않은 방식이며 반면에 Semi-supervised 방식은 weak supervision을 활용하지 않아 부분적으로만 성능을 끌어올릴 수 있다고 볼 수 있습니다.
이전의 fully weakly supervised 방식의 연구들은 weak labels에 strong labels를 단순하게 섞어버려 학습하는데 이를 NEEDLE 프레임워크에서는 weak labels의 노이즈를 억제하는 방식으로 완화하고 있죠.
그런 의미에서 본 연구는 supervised NER과 weakly supervised NER을 연결하는 다리와 같은 연구라고 볼 수 있습니다.
Comments powered by Disqus.