
개인적인 논문해석을 포함하고 있으며, 의역 및 오역이 남발할 수 있습니다. :)
1. Introduction
- 현존하는 대부분의 NER 방법들은 많은 양의 labeled data가 필요함
- 특정 도메인의 전문가가 직접 레이블링을 해야하는 경우, 사람의 노력이 많이 필요하며 시간도 많이 소요
- distant supervision: 자동적인 레이블링 할당 방법들이 제안되어 왔음
- 특정 도메인에 대한
raw corpus혹은dictionary를 사용 - 정확한 문자열 매칭(string matching)으로 레이블을 할당
- 위 방법으로 진행할 경우, 아래 두 가지 문제점이 존재할 수 있음
- 특정 도메인에 대한
- Incomplete annotations
- original dictionary에 entity가 모두 포함되지 않을 수 있음: out-of-dictionary
- 기존 데이터셋에
dictionary가 전체 domain entity에 50% 정도만 포함하고 있음을 확인
- 기존 데이터셋에
- 일부 선행 연구에서는 heuristic rule로
dictionary를 확장- 다른 도메인에 일반적으로 적용될 수 없음
- original dictionary에 entity가 모두 포함되지 않을 수 있음: out-of-dictionary
- the difficulty of recalling new entities
- supervised model을 통해 NER을 수행했던 선행 연구에서도 모델의 한계로 인해 새로운 entity를 찾아내는 것이 어려웠음
- 선행 연구에서는
sequence label model이나boundary detection model과 같은 방식으로 사용, 맥락적 정보(context information)만을 활용했음sequence label model: 문장의 단어마다 레이블을 예측하는 모델링boundary detection model: 문장의 특정 구간이 entity임을 예측하는 모델링
- 특정 도메인 corpus에 대한 전역적인 통계적 특징(global statistical features)은 선행 연구에서 배제되었음
- TEBNER: Type Expanded Boundary-aware NER)
- dictionary expansion
- raw corpus에서 높은 퀄리티의 어구(phrase)을 추출, 잠재적인 entity로 간주
- 수집된 어구에 entity typing model(with context information)로 분류 및 필터링
- 필터링된 어구들을
dictionary에 추가 - Incomplete annotations 문제 완화
- multi-granularity boundary labeling strategy
- 서로 다른 관점에서 문장 시퀀스를 태깅하고 이를 통해 명확한 entity boundary(문장 내 어느 범위가 entity인지)를 찾아냄
- token interaction tagger: entity token 간의 내부적 연결성 관점
- sequence labeling: 문장 내 명확한 entity 범위 관점
- global statistical features: 특정 domain corpus의 전역적 관점
- dictionary expansion
Contributions
- 애매한 방식이나 heuristic rule 등에 의존하지 않고 semantic context를 통한 새로운 dictionary extension method를 제안
- word, sentence, corpus level의 정보들을 통합(fusing)하여 entity boundary를 특정할 수 있는 Multi-granularity boundary-aware network 제안
- 세 가지 벤치마크 데이터셋에 대한 폭넓은 실험 설계 및 결과 제시
2. Related Work
Supervised Models
- 최근 일부 연구에서는 각 entity의 범위(boundary)만을 찾아내는 연구가 일부 있음
- 사전학습 모델의 등장에 따라 ELMo(Peters et al., 2018)나 BERT(Devlin et al.,2019)를 사용하여 NER 태스크를 수행
- 많은 양의 labeled data가 필요함
Distant supervision methods
- AutoNER; Shang et al., 2018b
- out-of-dictionary 어구들을 unknown type으로 매칭
- 잠재적인 entity 후보로 선정
- HAMNER; Liu et al., 2020
entity boundary를 예측하는 entity classification model을 도입
3. Problem Definition
- Named Entity Recognition
- 주어진 단어 시퀀스 $X = [x_1, x_2, …, x_n]$에서
- $t$ 타입의 entity 범위 $e_t = \left[x_i, …, x_j\right] (0 \le i \le j \le n)$를 찾아냄
- Distant Supervision NER
dictionary$D$를 입력으로 제공dictionary는 이름(surface name)과 entity type을 적어놓음
4. The Proposed Method
- 두 가지 요소로 구성
- Dictionary Extender
- NER 레이블을 생성
- target domain에 대해서 많은 어구(phrase)를 생성함
- Entity Recognizer
entity boundary와entity type을 예측
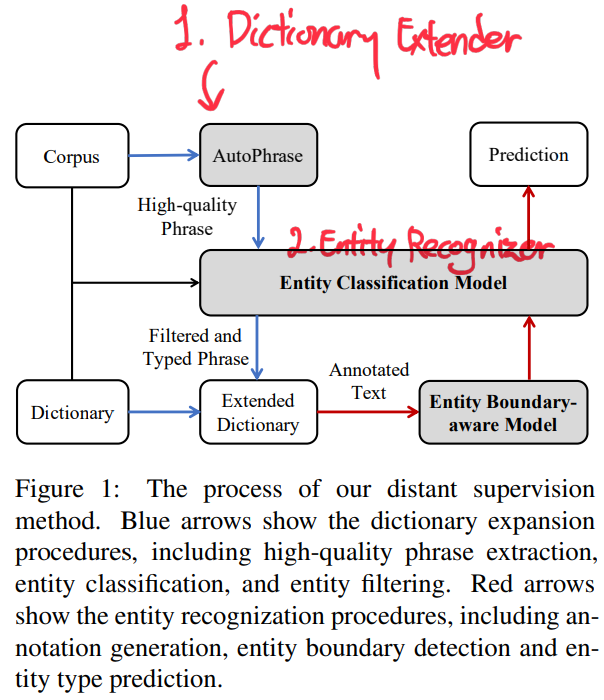
4.1. Dictionary Extender
- High-quality phrase extraction
- 선행 연구에서 처럼 AutoPhrase(Shang et al., 2018a)를 통한 어구 생성
- AutoPhrase
- distantly supervised phrase mining tool
- 빈도 수에 따라 후보 어구를 만들고 검증하며 어구를 생성하는 툴
- Threshold
- 좋은 퀄리티의 entity만을 확보하기 위한 임계값, AutoPhrase의 신뢰도 점수 기반
- single word phrase: 0.9
- multi-word phrase: 0.5
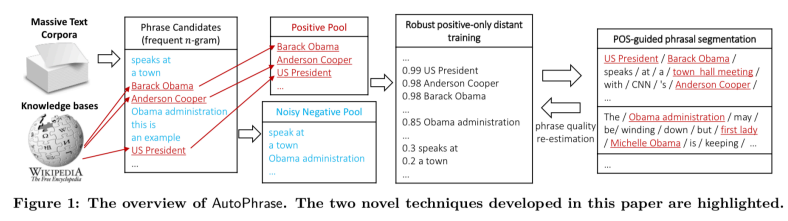 AutoPhrase의 아키텍처, Shang et al., 2018a
AutoPhrase의 아키텍처, Shang et al., 2018a
- Entity classification
- AutoPhrase가 생성한 어구 리스트를 필터링하는 과정
- Entity typing model을 아래와 같이 구성
- 일차적인 Entity 후보의 엔티티 타입을 예측
- ex.) $none$ type으로 예측되는 경우
dictionary에서 제외
PreTrained BERT > Linear > softmax를 태워cross-entropy로 학습BERT's input: $[CLS] \space ctxt_l \space [x_i] \space … \space [x_j] \space ctxt_r \space [SEP]$ (텍스트 시퀀스)Linear layer's input: $V_h = V_{[cls]} \oplus V_{[x_i]} \oplus V_{[x_j]}$Relu > softmax: $P(y_t\mid e_t) = softmax(W^2_t (Relu(W^1_t V_h + b^1_t)) + b^2_t)$cross-entropy: $L_{type} = -\sum_{i=1}^n y_i \log(P(y_i\mid e_i))$
- $none$ entity 추가
- Entity typing model이 $none$ entity type을 식별할 수 있도록
- AutoPhrase의 신뢰도 점수가 0.3보다 낮은 어구를 $none$ entity type으로 레이블링하여 학습 데이터에 추가
- AutoPhrase가 생성한 어구 리스트를 필터링하는 과정
- Entity Filtering
- Entity typing model의 예측 값이…
- $none$ entity type으로 분류된 어구 제거
- 여러 entity type으로 분류 예측된 어구 제거
- 남은 어구들을
original dictionary에 추가하여 확장 - 구성된
dictionary를 entity recognizer의 학습에 사용
- Entity typing model의 예측 값이…
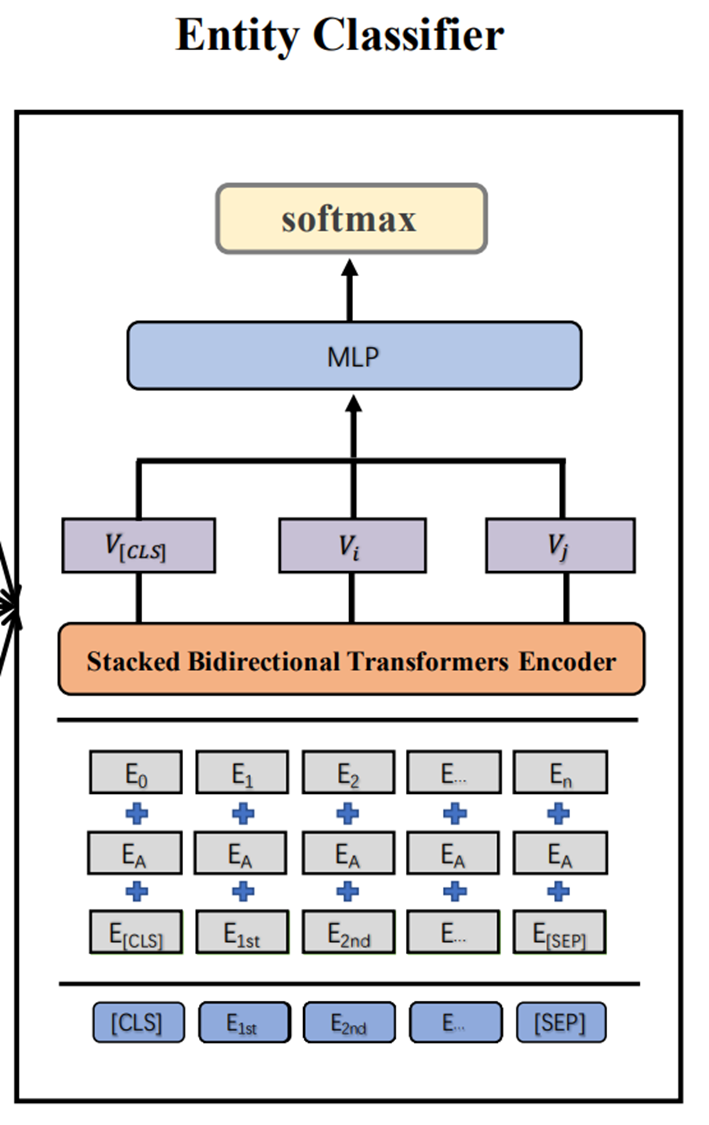
4.2. Entity Recognizer
- 개요
- distantly supervised 방식으로 레이블이 할당된 데이터는 error가 포함할 확률이 높음
entity boundary detection&entity classification을 동시에 모델링할 경우 과적합될 가능성이 높음- 따라서,
boundary,type classification을 각각 학습- Section 4.1.은
type classification의 학습 (Entity typing model) - Section 4.2.는
boundary의 학습 (token interaction model $M_w$, sequence label model $M_s$의 학습)
- Section 4.1.은
- 아래 3가지의 tagging schema를 fusing하여 다방면의 정보(multi-granularity)를 종합
- “Break or Tie” Tagging Schema ($M_w$)
- “BIO” Tagging Schema ($M_s$)
- “Phrase Matching” Tagging Schema (AutoPhrase)
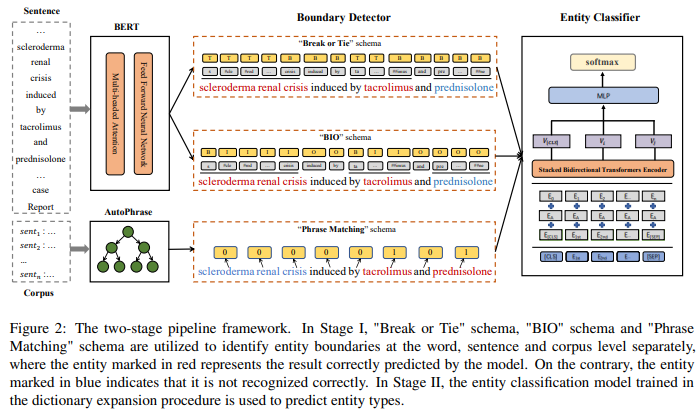
- “Break or Tie” Tagging Schema
- for word level entity boundary ($M_w$)
- entity가 분절되는 토큰들에 “Break”
- entity가 지속되는 토큰들에 “Tie”
- $M_w$: output representation from
BERT에 대해 아래와 같은 방식으로 학습- \[V^\prime_i = concatenate(i\text{-th token}, i+1\text{-th token})\]
- $i$번째 representation과 $i+1$번째 representation의 특징 결합
- \[P(c_i|V^\prime_i) = {\exp(c^T_i V^\prime_i) \over \sum_{c_k\in C} \exp(c^T_k V^\prime_i)}\]
- $C = \set{[Break], [Tie]}$
- $P(c_i\mid V^\prime_i)$: $V_i^\prime$이 토큰 $c_i$가 될 확률
- \[V^\prime_i = concatenate(i\text{-th token}, i+1\text{-th token})\]
 “Break or Tie”, 파란색 entity는 모델이 인식하지 못하는 경우를 가정
“Break or Tie”, 파란색 entity는 모델이 인식하지 못하는 경우를 가정
- “BIO” Tagging Schema
- for word level entity boundary ($M_s$)
- 기존의 NER 태깅 방식과 동일
- entity 범위가 시작하는 지점에 “B”
- entity 범위가 지속되는 지점에 “I”
- entity 범위에 속하지 않는 지점에 “O”
- $M_s$:
BERT > Linear > softmax학습- $C = \set{[B], [I], [O]}$
 “BIO”, 파란색 entity는 모델이 인식하지 못하는 경우를 가정
“BIO”, 파란색 entity는 모델이 인식하지 못하는 경우를 가정
- “Phrase Matching” Tagging Schema
- for corpus level entity boundary
- 선행 연구들은 corpus 내부의 통계적 특징들을 간과함
- AutoPhrase의 결과를 태깅
- corpus의 통계적 특징들을 반영한 AutoPhrase의 결과를 태깅했으니 통계적 요소를 반영하였다고 생각하는듯…?!
 “Phrase Matching”, 파란색 entity는 모델이 인식하지 못하는 경우를 가정
“Phrase Matching”, 파란색 entity는 모델이 인식하지 못하는 경우를 가정
- 결론
- 각기 다른 entity tagging 방식을 결합하여 마지막 분류의 입력으로 사용
Algorithm: The process of TEBNER

5. Experiments
5.1. Experiment Setup
- Dataset
- BC5CDR
- Chemical and Disease domain
- NCBI-Disease
- Disease domain
- LaptopReview
- review sentences
- AspectTerm mentions
- BC5CDR
- Training Details
- 사전 학습 가중치
- biomedical domain:
"biobert-base-cased-v1.1" - technical domain:
"bert-base-cased"
- biomedical domain:
- maximum sentence length:
256 tokens - hidden representation size:
786 - learning rate:
3e-5 - dropout probability:
0.15 AdamWoptimizer- Multi-layer perceptron for “entity classifier”: a depth of 2 and a hidden size of 256
- 사전 학습 가중치
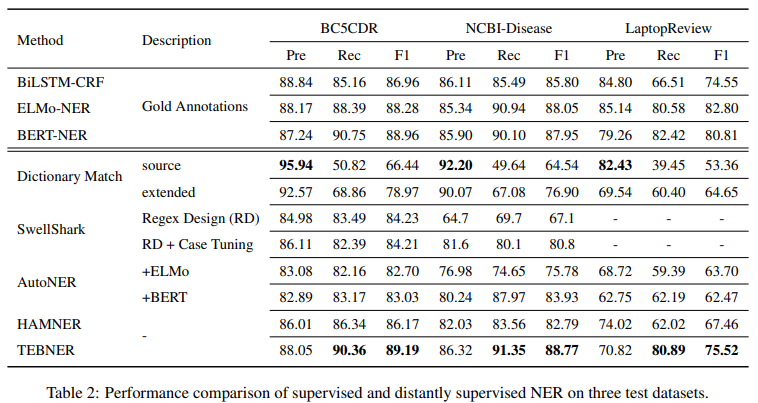
5.2. Comparing with Previous Work
- Baselines
- supervised model
- BiLSTM-CRF
- ELMo-NER
- BERT-NER
- distantly supervised model
- Dictionary Match: 주어진
dictionary$D$의 단순 string matching - SwellShark: biomedical 도메인에 특화된 방법, regular expressions가 필요하며 특별한 케이스에 대해선 직접 조정이 필요함
- AutoNER: BiLSTM 모델을 사용해 인접 토큰들의 연결성을 학습,
false-negative labels의 수를 줄임 - HAMNER: 기존 SOTA, headword-based matching을 통해
dictionary를 확장하고 entity typing model로 entity 범위(spans)를 예측
- Dictionary Match: 주어진
- supervised model
- Results
- AutoNER & HAMNER과 동일한
dictionary& phrases를 사용하였음에도 더 좋은 성능 - SwellShark가 biomedical 도메인에 특화된 구조이지만 더 나은 성능
- AutoNER도 “Break or Tie” tagging을 적용해 다방면의 정보를 종합하고자 했으나 인접한 토큰들의 연결성만을 모델링하여 성능이 떨어짐
- AutoNER & HAMNER과 동일한
5.3. Impact of Different Modules
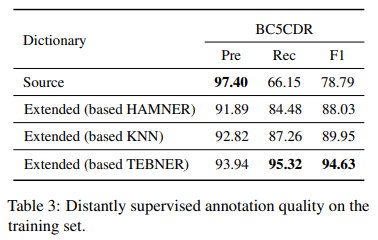
- Effectiveness of Dictionary Extension
- 복잡한 방법들을 사용하지 않았음
- ex). headword matching, semantic similarity calculation, annotations weight setting)
- 문맥적 의미 정보만을 사용해
dictionary확장- 어느 domain에나 적용할 수 있음
- 복잡한 방법들을 사용하지 않았음
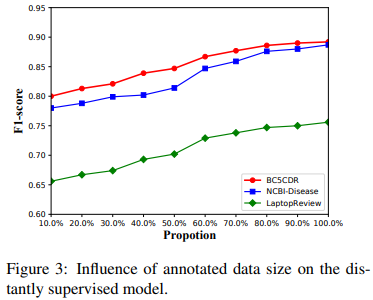
- Influence of the number of Annotations
- 확장한
dictionary로 만든 distantly annotations의 수를 조절하며 성능 비교 - 데이터의 수가 늘어날수록 증가하다가 80% 부근에서 수렴하는 경향이 있음
- 확장한
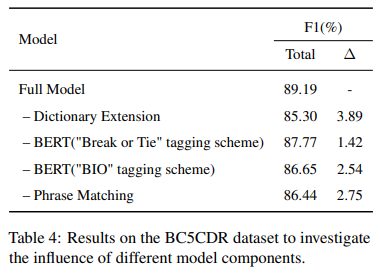
- Ablation studies
6. Conclusion
- 새로운 dictionary extension 방법 제안
- distant supervision 방식으로 특정 도메인에 적합한 boundary-aware model을 설계
- 어느 도메인에서나 적용될 수 있도록 entity classification model을 사용해
dictionary를 확장하였음 - 3가지 tagging schema를 적용해, 지역적 & 전역적 측면에서의 entity 인식을 시도하였음
Comments powered by Disqus.